


 (Aberdeen: búsqueda de información sobre el Data Lake actual, Michael Lock, vicepresidente senior de análisis e inteligencia empresarial)
(Aberdeen: búsqueda de información sobre el Data Lake actual, Michael Lock, vicepresidente senior de análisis e inteligencia empresarial)

Source: Datumize / Factor Daily
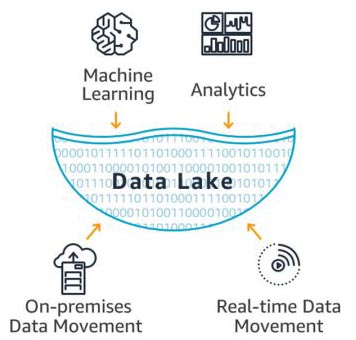
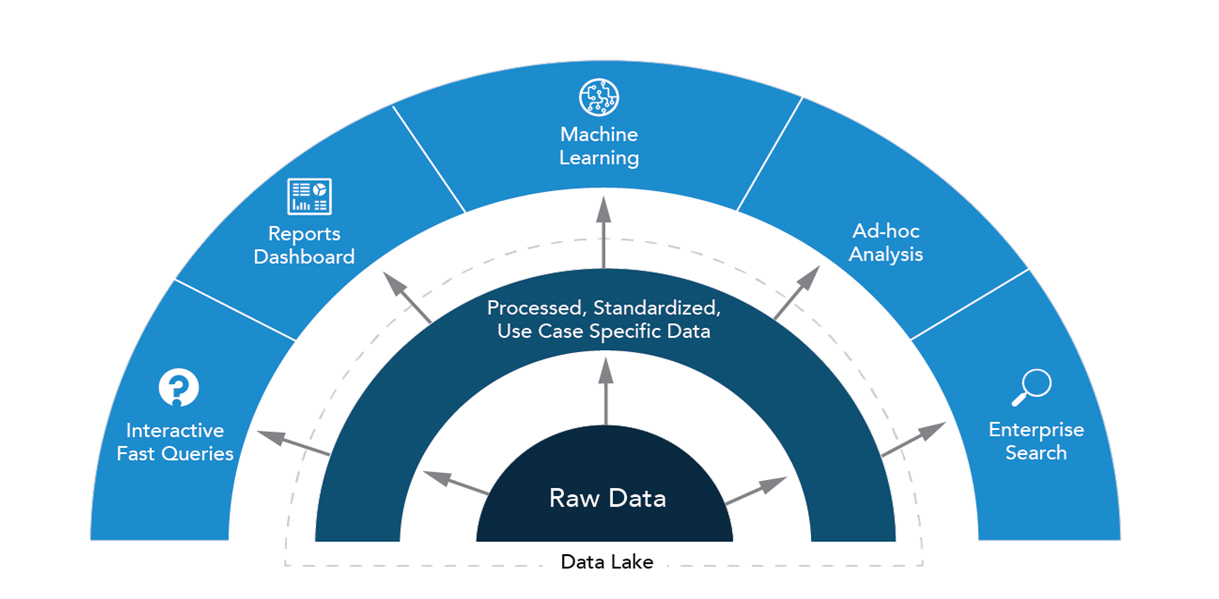
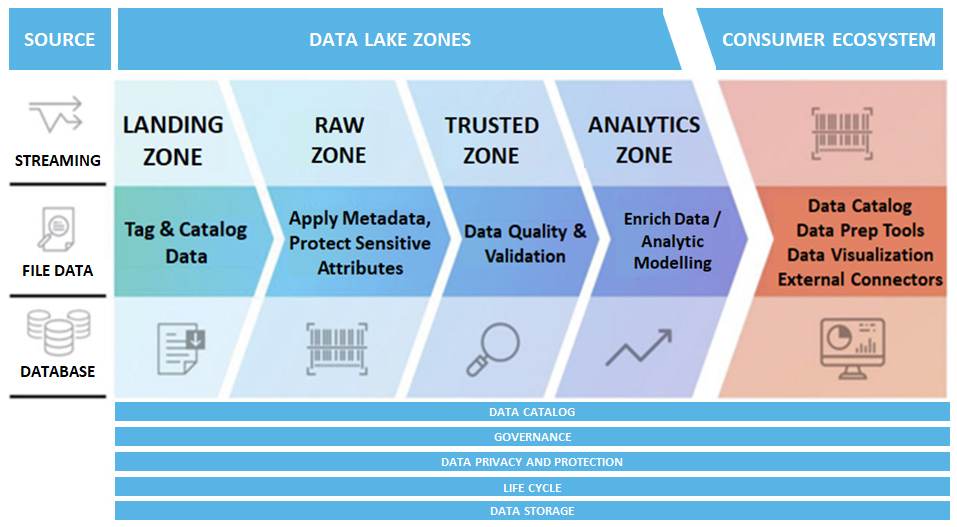
En esta era de iluminación impulsada por la tecnología, los datos son nuestra moneda competitiva.
La información en bruto, enterrada en los volúmenes alucinantes generados por los sistemas transaccionales … son conocimientos operativos, estratégicos y de clientes críticos que, una vez esclarecidos por el análisis, pueden validar o aclarar suposiciones, informar la toma de decisiones y ayudar a trazar nuevos caminos hacia el futuro.
Tracie Kambies, Nitin Mittal, Paul Roma, Sandeep Kumar Sharma Tendencias tecnológicas 2017, de https://www2.deloitte.com/content/dam/Deloitte/au/Documents/technology/deloitte-au-technology-dark-analytics-061017.pdf
Riesgo regulatorio:
Fuga o pérdida de información confidencial o información de identificación personal (PII)
Riesgo de propiedad intelectual:
- No proteger la propiedad intelectual
- Riesgo de oportunidad:
- Oportunidades perdidas de mejora